



转载:https://www.toutiao.com/article/7364399805688627723/
原创 2024-04-30 17:05・夕小瑶科技说
仅需上传模特图像,便可一键换装,极大提高了用户网购衣服的效率。
虚拟试衣(Virtual Try-On)作为图像生成中一个商业价值高、可以直接变现的子任务,研究热度随着图像生成技术的发展水涨船高。
但现有的一些方法生成的效果还差点意思,如下图所示:
基于GAN的方法换装后与模特不贴合,像是简单粗暴P上去的一样。扩散模型的出现使其可以生成逼真的试穿图像,但它们往往在细节上还原度不高,比如衣服的色彩版型与原始平装衣物不一致。
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
复旦团队认为扩散模型的随机性和潜在监督不足是导致问题的关键因素。为了缓解这些问题,作者为虚拟试衣(VTON)任务提出了一种新颖的忠实潜扩散模型――FLDM-VTON。
该方法在传统的潜在扩散过程的训练中从两个主要方面进行了改进:(i) 通过利用变形后的衣物作为起点和局部条件,提供忠实的衣物先验,以减轻初始和过程中的随机性,(ii)通过一个新颖的衣物平坦化网络,从原始平装衣物引入额外的图像级约束。结果显示,FLDM-VTON在性能上超越了最先进的基线,能够生成具有真实照片级逼真度和忠实衣物细节的试穿图像。
论文标题:
FLDM-VTON: Faithful Latent Diffusion Model for Virtual Try-on
论文链接:
https://arxiv.org/pdf/2404.14162.
方法概览
带有衣服先验的扩散模型
给定一个人像图像 和一个表示试穿区域的掩码 ,可以通过逐元素乘法得到一个无衣物的人像 ,表示试穿区域被遮罩的人像。虚拟试穿(VTON)的目标是将一件平铺的衣物 转移到 上,生成逼真的试穿图像,并保持衣物的细节。
以往的方法采用LDM 通过预训练的编码器 和解码器,在潜空间中训练一个扩散模型,包括前向和反向过程。在前向过程中,会在任意时间步向结果的潜在特征 中添加高斯噪声?,其中 是真实试穿图像。在反向过程中,使用扩散 U-Net 估计添加的噪声 ?。
传统的方法能产生逼真的效果,但在衣服细节的处理上还不够完善。因此本文以 或变形衣物特征 作为起点,其中变形衣物特征在开始时提供了衣物先验。将 称为主起点,称为先验 起点。此外,利用预变形的试穿图像特征 作为所有时间步的先验局部条件,其中 。
前向过程
在主起点 和先验起点 z_0^p 的潜在特征上逐渐添加高斯噪声 ?,在任意时间步t$,得到对应的 t-阶潜在特征。如下公式所示:
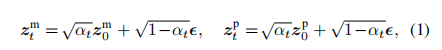
反向过程
将缩小的掩码 作为去噪条件,预扭曲的试穿图像特征 作为局部先验条件。我们将第个潜在特征、
 相关论坛
相关论坛
 相关广告
相关广告

 拨打电话
拨打电话